
File Configuration
This stage details the specific configuration for each source file being loaded as part of the automated data refresh
It contains:
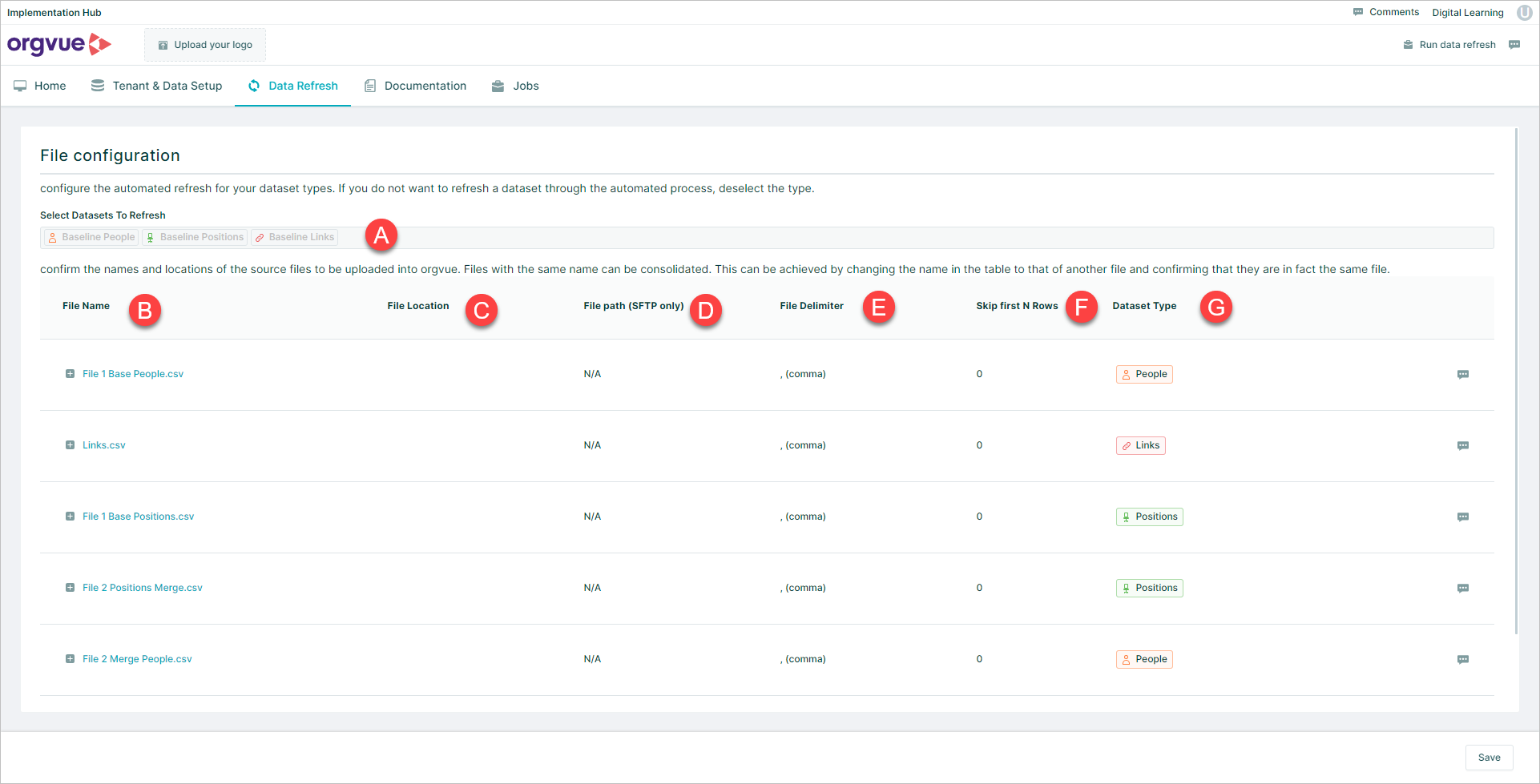
- A. Select Datasets To Refresh
- B. Load File Name
- C. File Location
- D. File path SFTP only
- E. File Delimiter
- F. Skip first N Rows
- G. Dataset Type
Select Datasets to Refresh
This section allows you to decide which datasets to refresh and which not to refresh
It is possible to turn off the refresh for any dataset no longer required by removing them from the text box
Clicking into the textbox, a drop down list will appear that allows selection or un-selection the specific datasets that have been configured
Note: Archiving cannot be turned off and so the archived datasets will be a copy of the current snapshot dataset
Load File Name
This field details the name of the file that Blender will look for when it tries to update the data in Orgvue
This field is populated from the Data Structure stage
To update the names of the files that Blender searches for:
- Click on the file name to edit
- Update the name of the source file, ensure you add .csv to the end
- Click
Applyto update the file configurations
File Location
The File location option reflects where the source file will be loaded from:
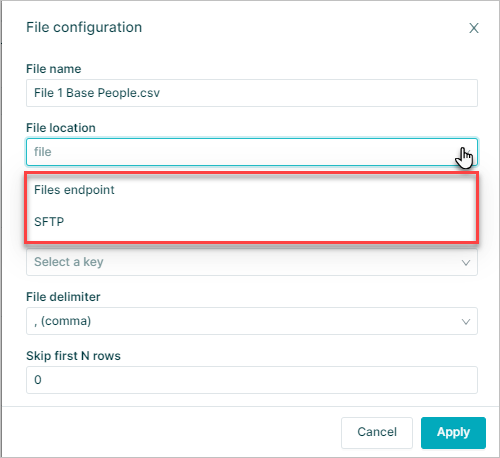
- SFTP (Secure File Transfer Protocol): This is the option that allows for a fully automated data refresh solution
The Orgvue Data Refresh Jobs Manager will go directly to the file server specified and take the file it is looking for - Orgvue File Endpoint: This option requires the user to upload their files to the files endpoint
This means some manual intervention is required before every refresh to ensure the most up-to-date file is in the endpoint
The default is orgvue file storage
File path SFTP only
This field is only required when the SFTP option is selected
This field gives the Data Refresh Jobs Manager the file path to the server where the file is being stored
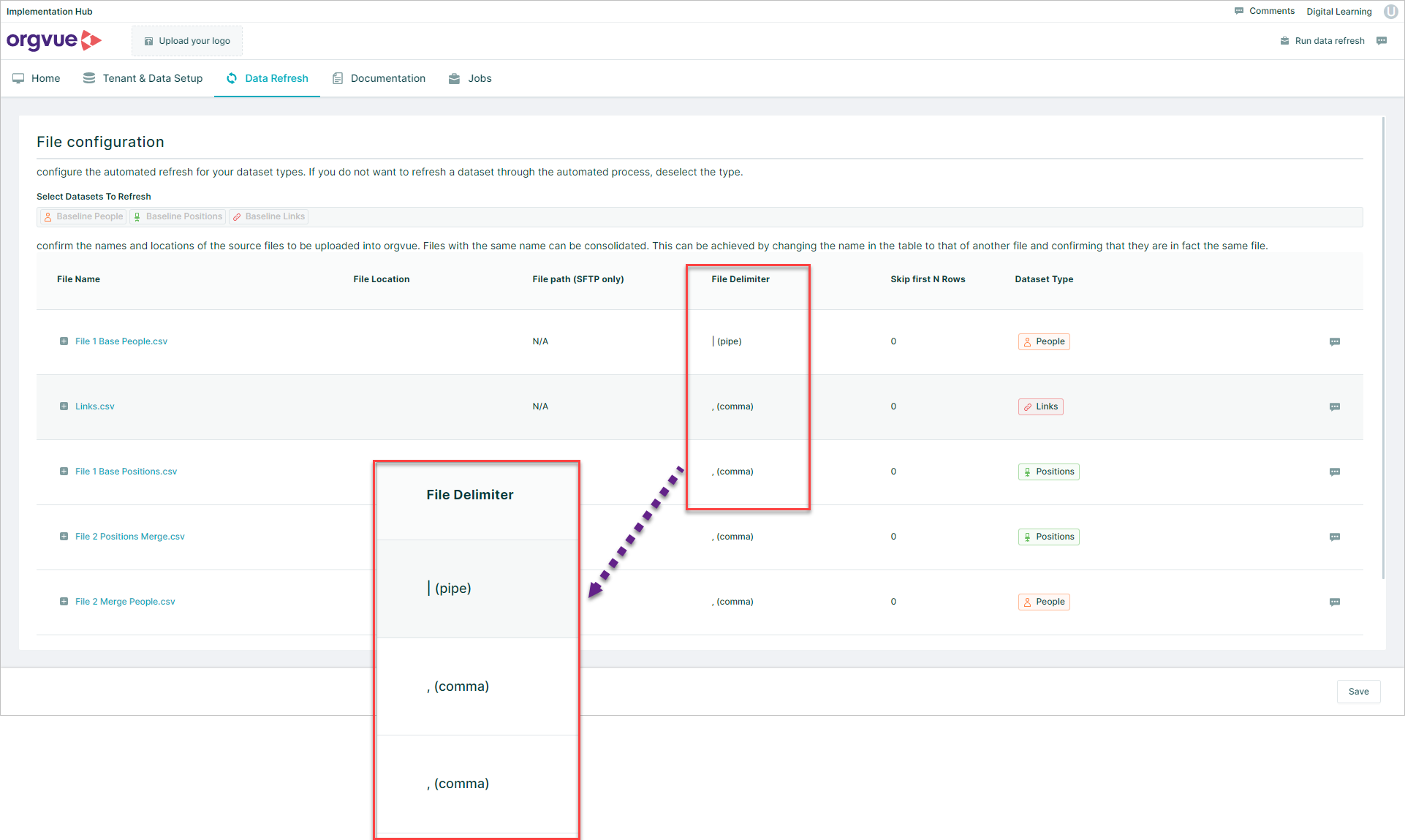
File Delimiter
This option specifies whether the .csv file is delimited by a | (pipe) or a , (comma)
The comma is the default option but can be amended if required
Skip first N Rows
N in this instance refers to any number
For example N = 1, N=0, N= 10. It tells Blender if you want to skip a specific number of rows in the file
This text box will have been configured in Implementation if the Data Refresh Jobs Manager is required to skip a specific number of rows in relation to your source file structure but is amendable if required
Dataset Type
This tells the Data Refresh Jobs Manager what the file type is
The options are people, positions or links dataset
- If Tenant Structure is set to
people onlyarchitecture, only people dataset types will shown - If Tenant Structure is set to
people, position and linksarchitecture the relevant dataset type will be shown
This is a non-modifiable field at this stage